

VM
•
l4
•
cpu 4, core 2 , 32 gb
•
storage 2000gb → 200gb 예정
•
nvidia-smi
◦
570.124.06
◦
cuda 12.8
train
•
wav 24gb
•
csv 10mb
tensor board
데이터 감정 갯수 / 가중치
감정 | 데이터 수 | 가중치 |
sadness | 13,984 | 1.38 |
angry | 11,633 | 0.54 |
disgust | 4,660 | 1.35 |
happiness | 4,547 | 1.52 |
fear | 4,131 | 1.93 |
neutral | 3,262 | 0.45 |
surprise | 1,755 | 3.58 |
테스트 1
•
superb/wav2vec2-base-superb-er
◦
외국어쪽 베이스에 맞춰져서 한국어의 고유한 억양과 톤이 학습되지 않아서 파인튜닝해도 효과가 없음
•
kresnik/wav2vec2-large-xlsr-korean
◦
한국어 학습된 모델로 변환
테스트 2. single task
학습 환경
•
모델 구조: Wav2Vec2SingleTask
•
입력 길이: 3초 (16kHz → 48,000 샘플)
•
에폭: 10
•
배치 사이즈: 4
•
Mixed Precision (FP16): 사용 안 함
•
총 스텝 수: 98,940
전체 학습 시간
•
총 학습 시간: 14시간 30분
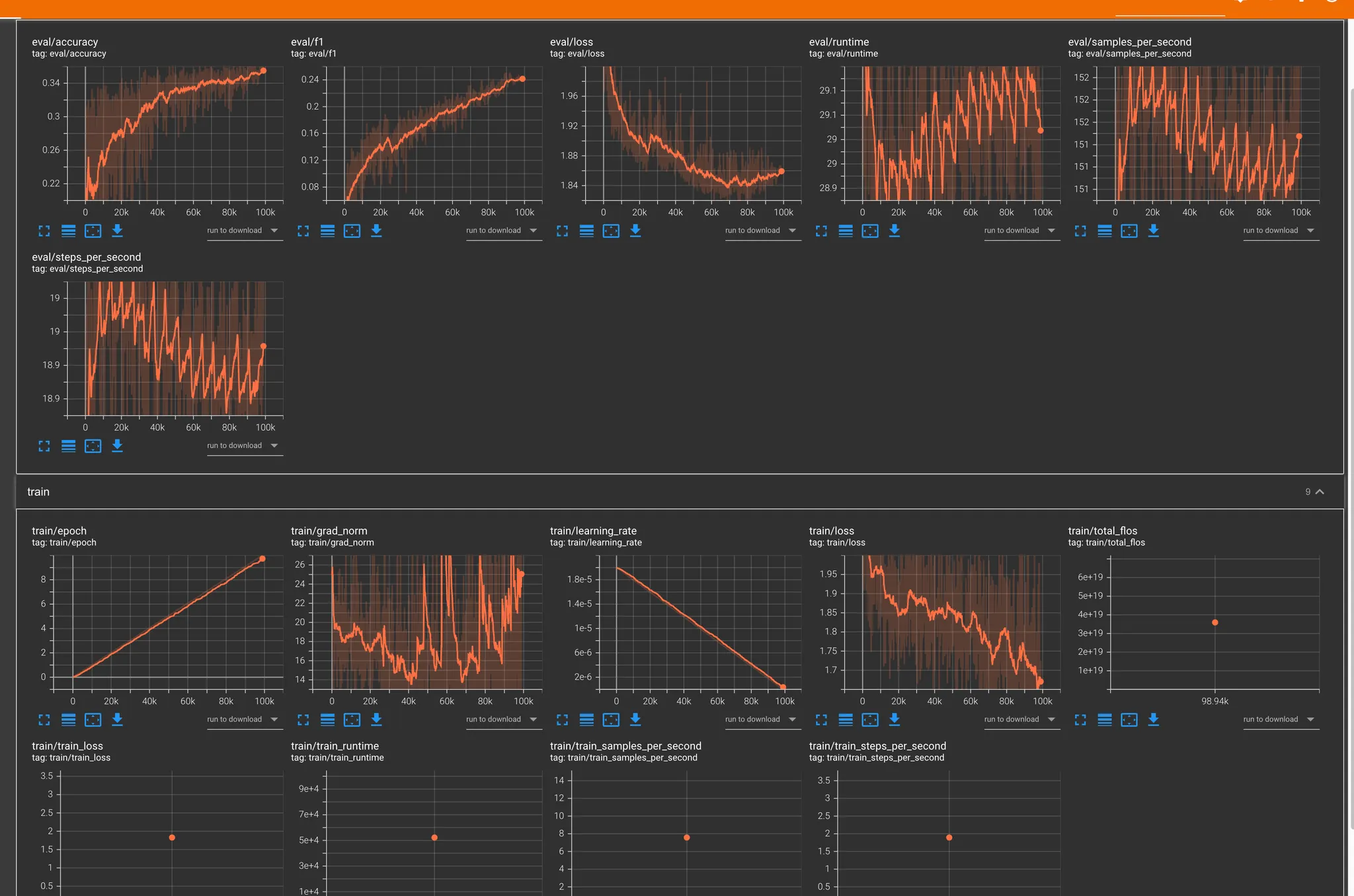
항목 | 결과 |
Accuracy | 0.35+ |
F1 Score | 0.24+ |
Eval Loss | 1.96 → 1.86 |
Train Loss | 1.73 |
Learning Rate | 0 |
Grad Norm | 살짝 튀었지만 일단 오키 |
예측 정확도 문제
•
대부분의 예측이 neutral에 편향됨
•
실제 사용자 음성에서 정확도가 낮음
•
데이터셋에서 적은 감정(label)의 예측률이 현저히 저조
복합 감정 처리 한계
•
다중 감정이 있어도 단일 감정만 선택 가능
•
유사 감정 간 구분이 어려움
•
softmax 점수 차이가 작아도 최고점만 선택됨
실험 결과 관찰
•
disgust 감정이 과다 예측됨
•
고른 softmax 분포에도 단일 출력만 가능
•
1초 단위 슬라이딩 테스트에서 감정 편향 발생
결론
단일 감정만 분류하는 Single Task 방식은 실제 서비스 요구사항을 충족시키기 어려움.
복합 감정 표현과 정밀한 예측을 위해 Multi-Task 기반 구조로 전환이 필요함.
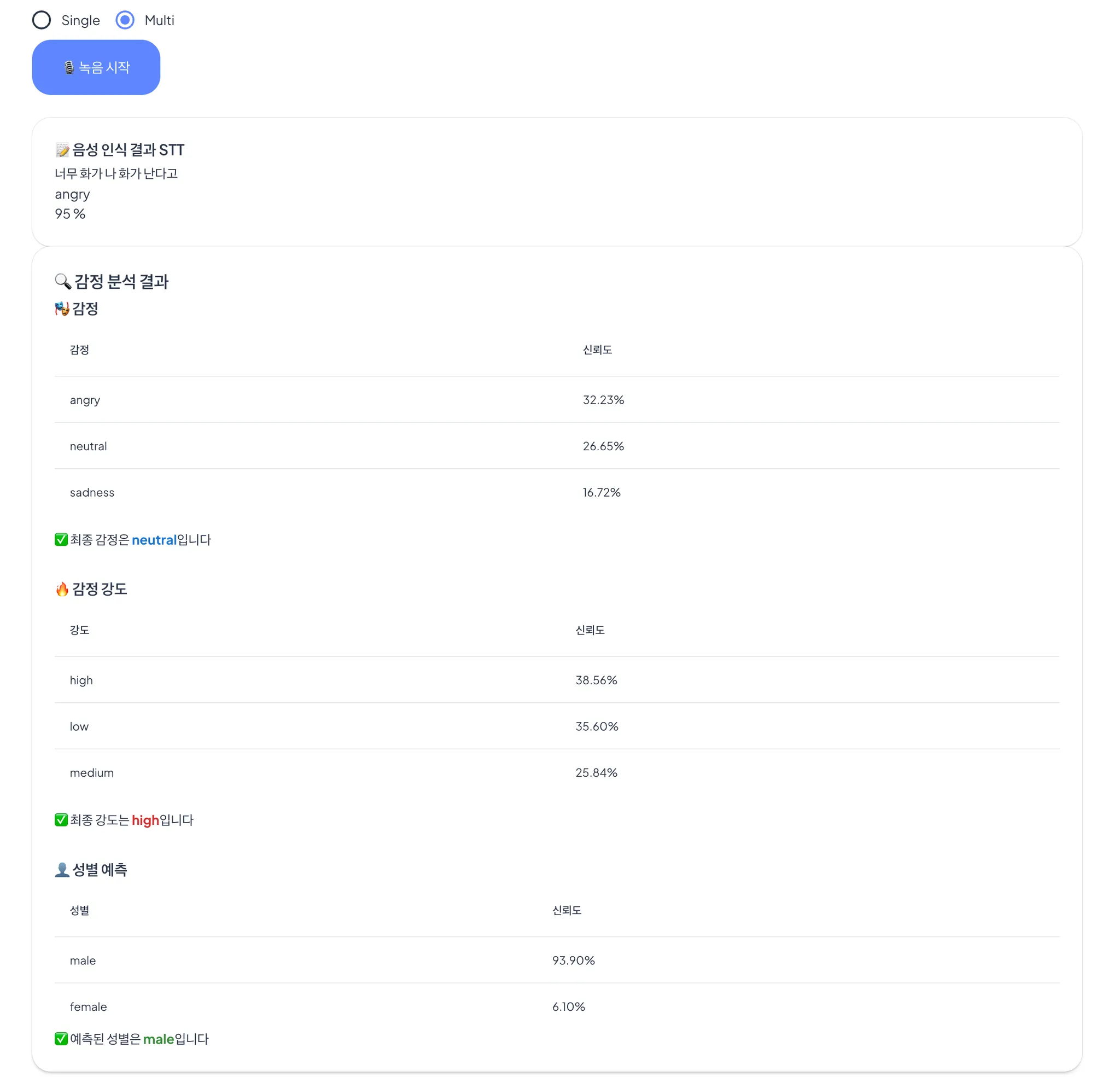
테스트 3. multi task + stt 감정평가 (3000개)
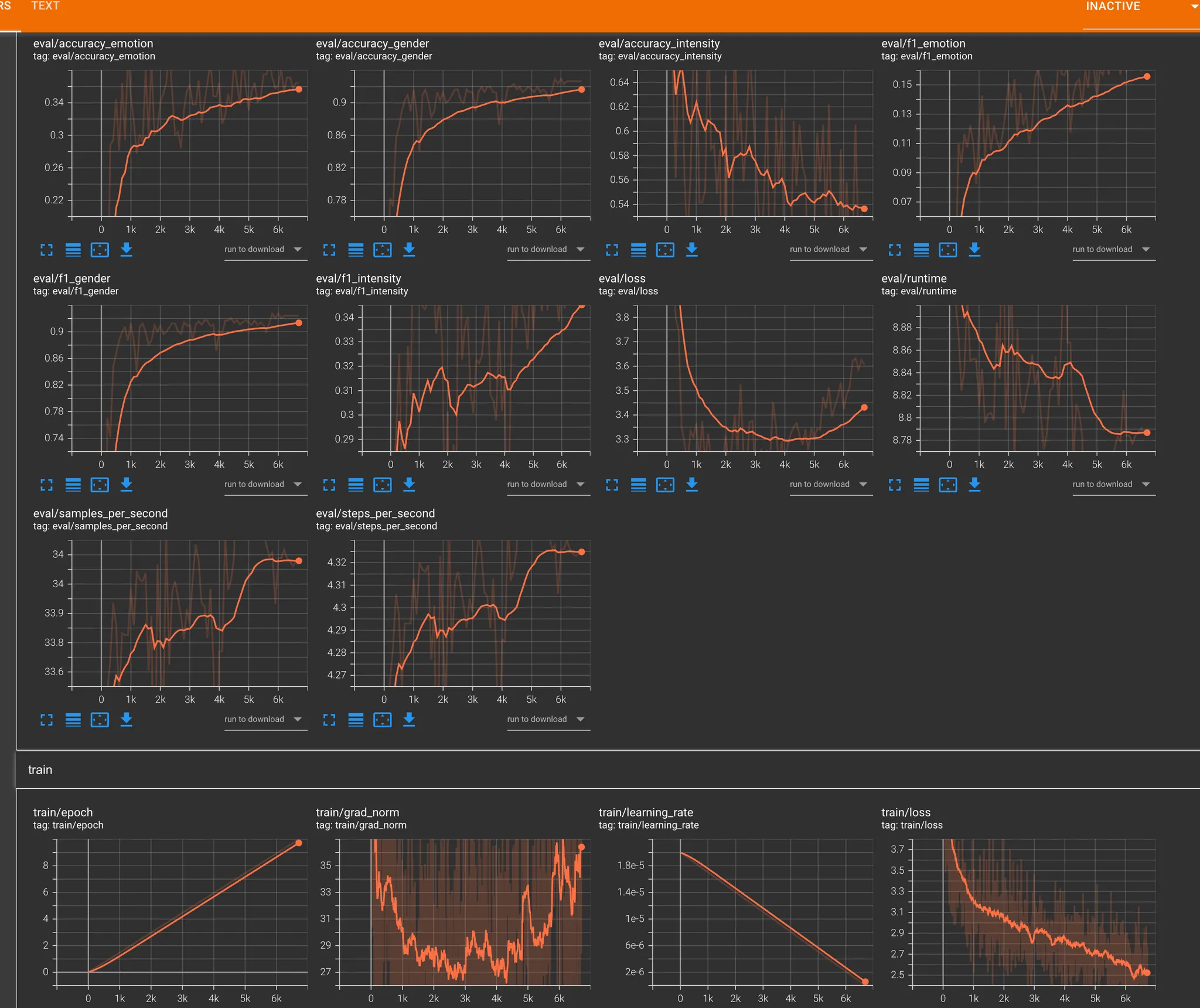
•
멀티테스크 학습으로 변경
◦
감정 (7개)
◦
어노테이션
◦
감정 강도
◦
성별
•
대략 20 시간 예상
테스트 4. multi task + stt 감정평가 (40,000개)
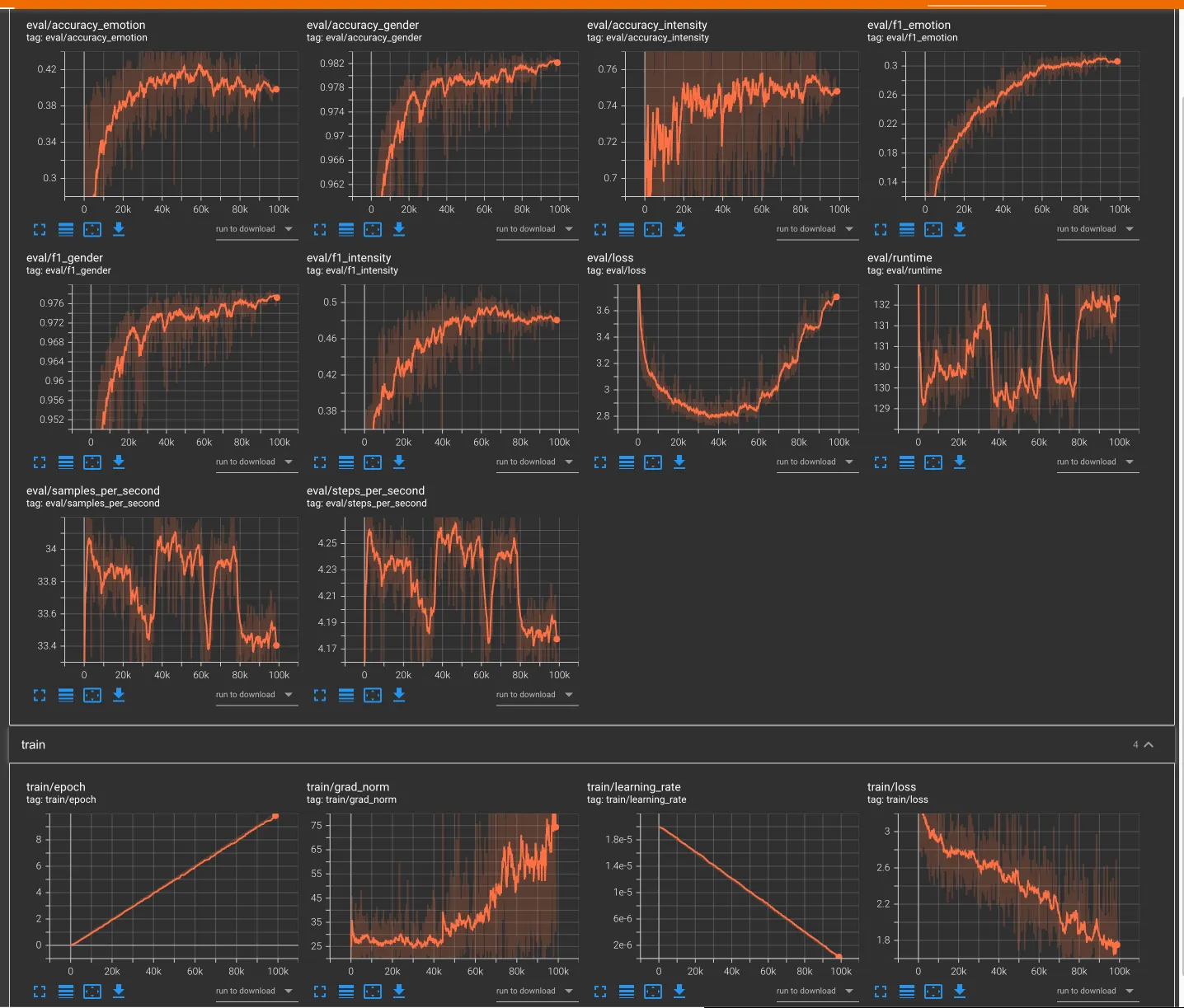

•
42시간
•
output : 약 8기가